The Completely Automated Public Turing test to tell Humans and Computers Apart, or CAPTCHA, as it’s more popularly known has been around for more than 20 years. But are you aware of the history behind it?
Completely Automated Public Turing test to tell Computers and Humans Apart (or CAPTCHAs as they’re more commonly known) have been a thing since the late ’90s and ever since, we’ve been told we need to prove we’re human in order to submit forms, make requests and other things that could be at risk of getting spammed by spam robots.
It may surprise you though, how much CAPTCHA boxes have had to adapt to cope with the ever-expanding learning mechanisms of robots and malicious scripts. They’ve always had to stay ahead of the robots – but how have they done this, and where did they begin?
The beginning of the CAPTCHA
The creation
In the 1990’s, the most popular search engine that people used was Altavista. Whilst it was the first of its kind for logging websites and links in its extensive database, it had a huge spam problem. People were creating automated robots that were sending malicious links into Altavista’s database of the web.
To combat the spam problem, Altavista added a question to the submission form that only humans could answer – they included a warped image of a word/letters or series of numbers (see below).

Image processing wasn’t quite up to the task of identifying warped numbers and letters – but humans were. That is of course if you had good eyesight, accessible versions didn’t come about until much later!)
The dawn of reCAPTACHA Version 1
A little bit after Altavista’s CAPTCHAs, ReCAPTCHAs were created, this involved reducing spam, and helping book scanning systems to identify words that they couldn’t read or identify. They used to look a little bit like this:
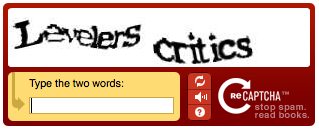
One of the words in the box was a word that was known to the system and would verify that it was a human answering it (this was the one people needed to get right). Then, there was an unknown word, a word that the systems didn’t know. Once a number of people had typed in the same word for this ‘unidentified’ word, it would be logged as part of the book scan.
Of course, Google soon bought ReCAPTCHA and used it as their own.
The CAPTCHA arms race.
Of course, now that these security ‘checkpoints’ had been placed on almost all of the forms on the internet, the bot makers and spammers were on the case of teaching robots how to solve these. They looked at ReCAPTCHA as a challenge.
A lot of the time, bot makers and spammers would teach fairly simple robots how to read these jumbled words and numbers. And for those words that the bots couldn’t identify? They could simply pay humans a minimal amount to solve ReCAPTCHAs. Or they could simply choose from one of the many companies that offered CAPTCHA-solving services.
The CAPTCHA upgrade.
ReCAPTCHA Version 2
Once Google had caught on to the fact that bot makers and spammers had been breaking through their ReCAPTCHA systems they worked on an update: ReCAPTCHA Version 2. Which, for the most part, looked like a simple checkbox that says, ‘I’m not a robot’.
Surprisingly, bots did not suddenly develop consciousness and have an existential crisis when faced with this box; this CAPTCHA isn’t actually about checking the box. This CAPTCHA is linked with google.com and, although Google will never reveal exactly what it is it, data gets passed between Google and this CAPTCHA. Theoretically, it can look at all of your login cookies and search history, as well as tonnes of other data from your Google Account and browser (if you’re using Chrome).
The secondary check
Of course, ReCAPTCHA Version 2 is pretty secure, it essentially runs an Internet background check on you to make sure you’re human. But what if you’re using Incognito Mode? What if you’re a brand-new computer user with no tracking or cookie data? That’s where their secondary checks come in.
Google has combatted this issue with their secondary check box, where you’ll have to do things like identify all of the cars in a series of nine images, ‘click the boxes that contain a fire hydrant’ or ‘click on the pictures containing a shop’ – the list goes on.
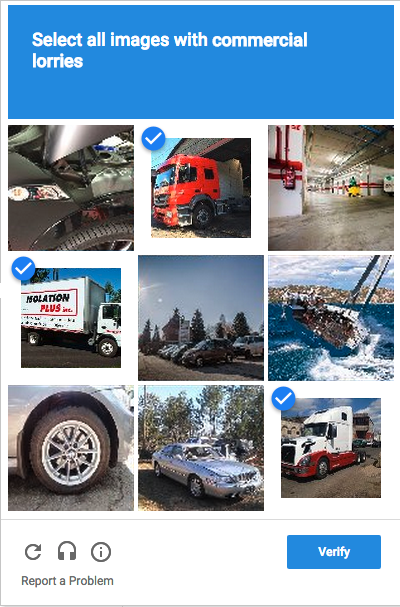
But, like all CAPTCHAs, bot makers have seen this as a challenge and with the advancement of machine learning and AI, they can essentially create their own tracking and search history. And the secondary tests? They’re easily beaten by cloud machine learning systems. And given that Google Cloud sells machine-learning systems, it’s entirely likely that some of their servers are creating CAPTCHAs, and others are breaking them.
The Future of CAPTCHAs
ReCAPTCHA Version 3
In the last year, Google has started to roll out reCAPTCHA Version 3. And, unfortunately, there’s not much that can be said for this, because it’s such a closely guarded secret. All that we do know is, from the minute you enter a website with reCAPTCHA Version 3 on it, you will be monitored in the background, and when you go to click ‘submit’ you’ll have already been assigned a ‘How Likely This is to be a Robot’ score.
There are no documents detailing how they work this out, and we can only hope that they are taking into account Incognito Mode, and importantly, accessibility tools. For all we know, those with a negative score may have their comment immediately archived or their form submission sent into a spam folder. And there’s no way to tell if you’ve failed.
Facial recognition
Something that Monzo Bank is doing, is a sure-fire way of ensuring you’re not a robot. Their identification checks involve you sending a picture of your ID, and thereafter sending a video of you saying a phrase. Not only is this checking you are a human, but it’s also ensuring you’re the specific human in question.
The takeaway
Unfortunately, as bots get more and more advanced, CAPTCHA methods will have to become more and more intrusive to establish that you are in fact human. Users will need to sacrifice more of their privacy in order to remain safe from spam and bots on the internet, and by the looks of things, it’s something we’ve got to accept.
{kind=link}